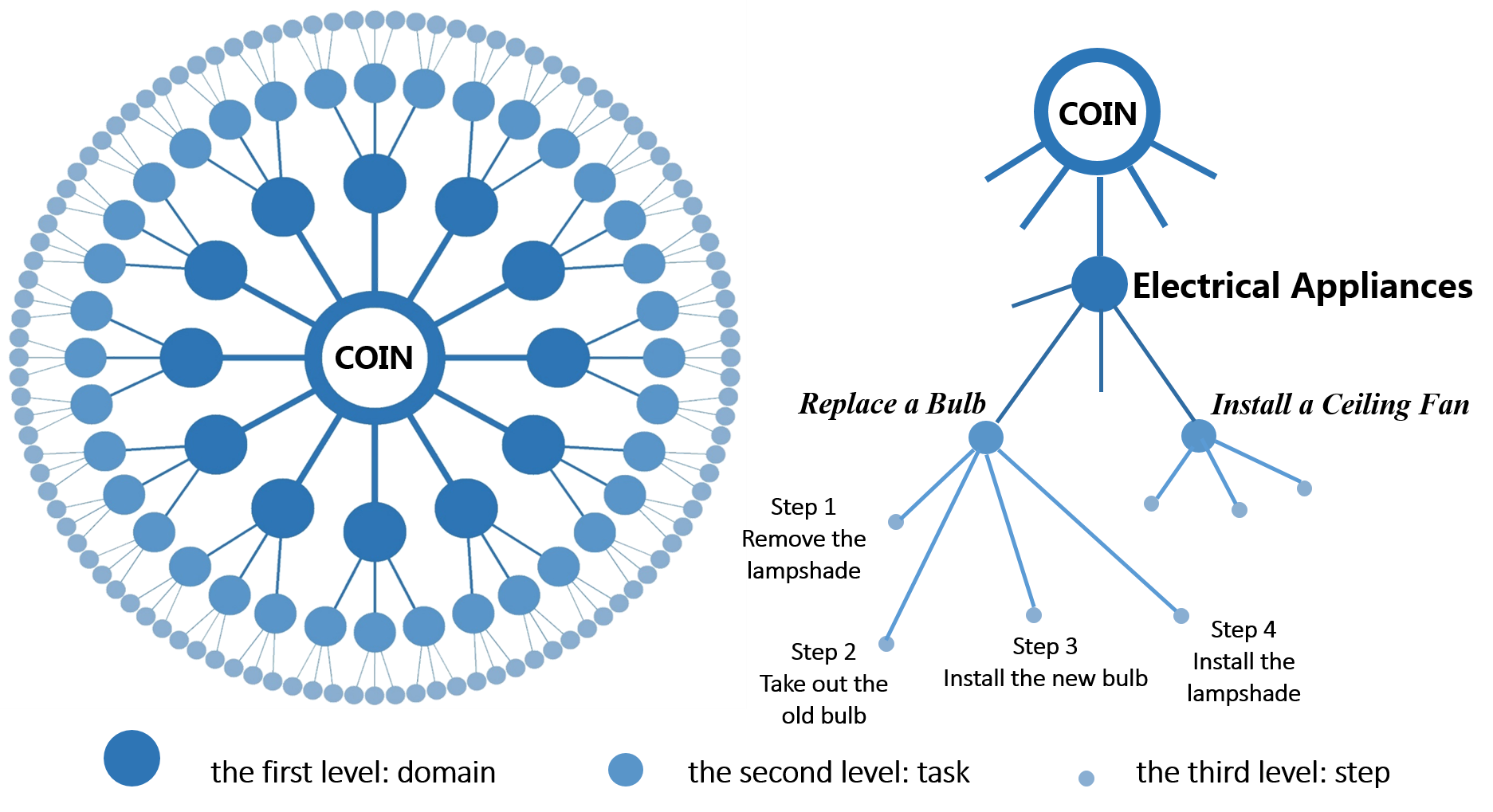
Towards the goal of constructing a large-scale bench-mark with high diversity, we proposed a hierarchical structure to organize our dataset. The figure above presents the illustration of our lexicon, which contains three levels from roots to leaves: domain, task and step.
• Domain: For the first level of COIN, we choose 12 domains as: nursing & caring, vehicles, leisure & performance, gadgets, electric appliances, household items, science & craft, plants & fruits, snacks & drinks dishes, sports, and housework.
• Task: As the second level, the task is linked to the domain. For example, the tasks "replace a bulb" and "install a ceiling fan" are associated with the domain "electrical appliances".
• Step: The third level of the lexicon are various series of steps to complete different tasks. For example, steps "remove the lampshade", "take out the old bulb", "install the new bulb" and "install the lampshade" are associated with the tasks "replace a bulb".